Neural Network Compression FAQ
Matt Mahoney
mmahoney@cs.fit.edu
Last update: Mar. 25, 2000
This FAQ is for Fast Text Compression with Neural Networks.
How does your neural network compression program work?
It is a predictive arithmetic encoder, similar to PPM, but using
a neural network instead of n-gram statistics to estimate probabilities.
A predictive encoder has two parts (see below). The first part is the
predictor: it assigns a probability to each character in the alphabet
that it will occur next. The second part is the encoder. It peeks
at the next character and assigns a code based on the probability
assigned to it by the predictor. The idea is to assign short codes for
the most likely characters, so that the output will be shorter on average.
Compression P(a) = .04
+-----------+ P(b) = .003 +---------+
the cat in th_ --> | Predictor | --> ... --> | Encoder | --> X
+-----------+ P(e) = .3 +---------+ |
... ^ |
e --+ |
|
+----------+
Decompression P(a) = .04 v
+-----------+ P(b) = .003 +---------+
the cat in th_ --> | Predictor | --> ... --> | Decoder | --> e
^ +-----------+ P(e) = .3 +---------+ |
| ... |
+---------------------------------------------------------+
During decompression, the predictor makes an identical series of
probability estimates for each character. But now the decoder does
the opposite of the encoder. It matches the code to what the encoder
would have assigned to each character in order to recover the
original character.
How does encoding work?
We start with a range from 0 to 1, and divide it up in proportion to
the input probabilities from the predictor.
For instance, common letters like e and
t get larger slices than rare letters like q and z.
Then the encoder peeks at the next letter, and selects the corresponding
slice to be the new (smaller) range. This is repeated for each input
character. For instance, the input the might be encoded as follows:
0 .7 .8 1
+-----------------------------------+
| a |b| c|d| e | ... | t | ..... |
+-----------------------------------+
/ \
/ \
.7 .74 .76 .8
+-----------------------------------+
| a |||| e || h | i |||| o |..|
+-----------------------------------+
/ \
/ \
.74 .746 .752 .76
+-----------------------------------+
| a || e || i | .. | "the" = .75 (11 in binary)
+-----------------------------------+
The final output is a number, expressed as a binary fraction, from
anywhere within the resulting range. In the example above, we could
pick 0.75 (.11 in binary) because it is between .746 and .752. Thus, the
steps to encode the are:
- Predictor assigns, say, P(a) = .07, P(b) = .01, ..., P(t) = .10, ...,
P(z) = .001
- Encoder sorts the input, assigns [0, .07] to a,
[.07, .08] to b, ..., [.70, .80] to t, ...
- Next input character is t, new range becomes [.70, .80]
- Predictor (knowing the last letter was t) assigns
P(a|t), P(b|t), ..., P(h|t) = .2, ... P(z|t)
- Encoder assigns a subrange to each letter, including 20% to h:
[.74, .76]
- Next letter is h, new range becomes [.74, .76]
- Predictor assigns P(a|th), P(b|th), ... P(e|th) = .3, ...
- Encoder assigns [.746, .752] to the
- Input is e, new range is [.746, .752]
- End of input, output a number in the resulting range, say .75
(11 in binary)
The decoder knows the final result, (.75 or 11 binary). Thus the steps
for converting this back to the is:
- Predictor assigns exactly the same probabilities as before,
P(a) = .07, P(b) = .01, ..., P(t) = .10, ..., P(z) = .001
- Encoder sorts the input, assigns [0, .07] to a,
[.07, .08] to b, ..., [.70, .80] to t, ...
- Code is .75, so select t
- Predictor (knowing the last letter was t) assigns
P(a|t), P(b|t), ..., P(h|t) = .2, ... P(z|t)
- Encoder assigns a subrange to each letter, including 20% to h:
[.74, .76]
- Code is .75, so next letter must be h
- Predictor assigns P(a|th), P(b|th), ... P(e|th) = .3, ...
- Encoder assigns [.746, .752] to the
- Input is .75, so new range is [.746, .752] and output is e
Why use arithmetic encoding?
Predictive arithmetic encoding is within 1 bit of optimal, assuming
the probabilities are accurate. Shannon proved in 1949 that the best we
can do to compress a string x is log2 1/P(x) bits.
In our example, we have P(the) = P(t)P(h|t)P(e|th) = 0.1 x 0.2 x 0.3 = 0.006,
and log2 1/0.006 = 7.38 bits. We can always find an 8 bit
code within any range of width 0.006 because these numbers
occur every 1/28, or about every 0.004.
Why is log2 1/P(x) bits optimal?
Shannon proved this, but intuitively, we want to use the shortest codes
for the most likely strings. As P(x) increases, log2 1/P(x)
decreases.
The proof is easy for the simple case where all strings are equally likely.
If there are n possible strings each with probability 1/n, then we would
have to assign codes (in binary) of 0 through n-1. In binary, the
number n-1 has é log2 n
ù bits.
Samuel Morse developed one of the first
compression codes when he assigned short codes like "." for e
and "-" for t, and long codes like "--.." for z.
Why not just assign a code to each character?
It is less efficient because the codes must be rounded to a whole number
of bits for each
character instead of once for the entire input. Huffman codes (like
the UNIX pack program) use this technique, but the compression is
not very good.
For instance, suppose we had to compress strings like acbcaccbbaac
where a, b, and c each occur with probability 1/3. We
might use the following code:
Thus, abc = 01011. The average code length is (1 + 2 + 2)/3 = 1.667
bpc (bits per character).
We could do better by coding two characters at a time:
- aa = 000
- ab = 001
- ac = 010
- ba = 011
- bb = 100
- bc = 101
- ca = 110
- cb = 1110
- cc = 1111
and the average code length is (7 x 3 + 2 x 4)/(9 x 2) = 29/18 = 1.611 bpc.
Arithmetic encoding assigns a single code to the entire string, so no
more than one bit is wasted. If we have n characters in string
x, then P(x) = 1/3n, and the best we can do is
1/n log2 1/P(x) = log2 3 = 1.585 bpc.
How is arithmetic encoding implemented?
In practice, we don't keep the entire range in memory. As soon as a leading
digit of the code is known, we can output it. For instance, returning
to our encoding of the and using decimal encoding:
- t = [.70, .80], store x1 = 70, x2 = 80 in memory.
- th = [.74, .76], output 7, store x1 = 40, x2 = 60
in memory.
- the = [.746, .752], store x1 = 46, x2 = 52 in memory.
Here we keep the last two digits of the range in the variables x1
and x2, which can range from 00 to 99. In practice, we work in
base 256 instead of base 10, and we keep the last 4 digits (32 bits)
in memory.
Thus, we output one byte at a time, so we can waste up to eight
bits instead of one. Also (returning to our decimal example), we
store x2 - 1, i.e. [.70, .80] would
be represented by x1 = 70, x2 = 79 (allowing us to output the 7).
Some loss of efficiency
occurs because we have to round off probabilities in order to divide
the range [x1, x2] on integer boundaries. In practice, we lose less
than 0.0001 bpc.
How do you assign probabilities in the predictor?
Now we have come to the heart of the problem. Since arithmetic
encoding essentially solves the coding problem, compression performance
depends entirely on how well the predictor does.
For compressing text, solving the prediction problem (language modeling)
implies passing the Turing test for artificial intelligence,
a problem that has remained unsolved since Turing first proposed it
in 1950. Shannon estimated (also
in 1950) that the entropy of written English text (i.e. the best compression
possible in theory) is between 0.6 and 1.3 bpc.
(My research suggests
1 bpc). The best language model, one by Rosenfeld in 1996, achieved
about 1.2 bpc on hundreds of megabytes of newspaper articles. On smaller
files, 2 bpc is typical of good compressors, and 3 bpc for popular
formats as zip, gzip, and compress.
The problem is even harder than this for general purpose compression.
For example, suppose we take a 1 gigabyte file of zero bits and encrypt
it with triple DES (or some other strong encryption) using the key
"foobar". The output will appear to be a random string of 0's and 1's,
and no known compression program (including mine) will obtain any
compression on it whatsoever. Yet, I just described the file exactly
in the second sentence of this paragraph, in a lot less than one gigabyte.
A general purpose compression program should therefore do at least as
well as my description, but that implies that it must be capable of
breaking DES and every other known encryption system.
It gets worse. It can be proven that there is no compression algorithm
that will compress every input string. If there were, then the compressed
code could be compressed again, obtaining more compression. This could
be repeated until the code had length 0. Obviously, this code could
not be decompressed, since any string could have produced it.
In short, there is no best compression algorithm for all types
of data.
How does text compression solve AI?
As I mentioned, compression depends entirely on the accuracy of the
predictor, how well it estimates P(x) for any given string x.
The Turing test for AI was proposed in 1950. Turing stated that if
a machine is indistinguishable from a human communicating through a
terminal, then the machine has AI.
Humans are very good at ranking probabilities of text strings, for instance
P(the big dog) > P(dog big the) > P(dgo gbi eht).
This is also true of dialogues or transcripts, for instance,
P(Q: What color are roses? A: red) >
P(Q: What color are roses? A: blue).
If a machine knew this distribution, it could generate responses to
an arbitrary question Q such that the response A would have
the distribution P(QA)/P(Q). By definition of P, this is
exactly how a human would respond.
(Actually P varies among humans, but
this works to the advantage of the machine. For details, see my paper
Text Compression as a Test for Artificial
Intelligence, 1999 AAAI Proceedings).
So does your program solve AI?
No. It compresses to about 2.0 to 2.2 bpc. If it solved AI, it
would get 1 bpc. Like all languge models, there is room for improvement.
What are some ways to predict text?
The simplest method is to look at the last few characters (the context)
and predict based on what happened before in the same context. For instance,
if the last 2 characters are th, then we can estimate the probability
that the next letter is e is P(e|th) = N(the)/N(th), where N(x)
is the count of the occurrences of x in the previous input. This works
if the counts are large, but if N(th) = 0 (the context has not been
seen before), then we must fall back to a shorter (order 1) context, and
estimate P(e|h) = N(he)/N(h). If the context h is also novel, then we
fall back to an order 0 context: P(e) = N(e)/N.
This method is known as PPM, or Prediction by Partial Match.
Some of the best compression programs, rkive and boa,
use a variant called PPMZ, developed by Bloom in 1997.
If PPM works so well, why do you use a neural network instead?
PPM only works for character level models. So do all other popular
compression algorithms such as Limpel-Ziv (used in compress, zip, gzip,
gif), and Burrows-Wheeler compressors (szip). However, there
are other types of redundancies in text:
- Word order models, such as P(dog | the big), where
the units are words rather than characters. These
work best if we know where to divide the words. This is not as
simple as it sounds. For instance, New York is one word
(because its parts cannot stand alone), and apples
is two words (apple and -s).
- Semantic models. Observing a word like rose increases the
probability of observing related words like red, fragrence,
flower, garden, etc.
- Syntactic models. These understand ordering constraints among
nouns, verbs, adjectives, etc.
Does your neural network program use these other models?
No. It is strictly a character model like PPM, Limpel-Ziv, etc.
Then why did you use a neural network?
Because I wanted to develop a framework for adding the more advanced
modeling techniques. Most of these techniques have already been modeled
using neural network or connectionist systems, but never in a text
compressor.
A neural network also resembles the one known working language model,
the human brain. Developing a system like this might lead to a better
understanding of how humans process language.
What is the neural network doing?
It is predicting characters based on context.
It is equivalent to a 2 layers network, with one input (xi)
for each possible context and one output (yj)
for each character in the alphabet (below).
There is a weighted connection (wi,j, not all of them are shown)
between every input and every output.
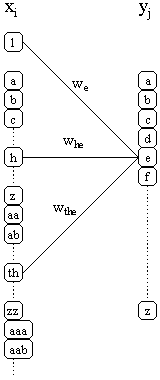
To make a prediction, such as P(e|th) (that th will be followed by
e), all of the contexts that are present (1, h, and th)
are set to 1, and all others to 0. (The input labeled "1", representing
the 0-order context, is always on). Then the outputs are calculated
as follows.
yj = g(Si
wi,jxi)
where g(x) = 1/(1 + e-x)
Then yi is the probability that character i is next.
For example, P(e|th) = g(we + whe + wthe).
The g(x) function has a range (0, 1), so it always represents a valid
probability. It is an increasing function. For instance:
- g(-4) = 0.018
- g(-2) = 0.119
- g(-1) = 0.269
- g(0) = 0.5
- g(1) = 0.731
- g(2) = 0.881
- g(4) = 0.982
How are the weights determined?
They are set adaptively. Initially, all of the weights are 0. Then
after each prediction we look at the actual character and adjust all
of the weights in order to reduce the error. The adjustment has
the form
wi,j ¬ wi,j +
nxiEj
where Ej = yj - P(j) is the error, the difference
between the actual and expected next character, and the constant
n is the learning rate.
Thus, in our example, if the next character is e, then we increase
we, whe, and wthe, and decrease all
of the other weights connected to the inputs 1, h,
and th. Note how this increases the predicted probability
of e the next time any of these contexts occur again.
What is the learning rate?
This determines how fast the weights are adjusted. Usually this
is set ad hoc to around 0.1 to 0.5. If the value is too small,
then the network will learn too slowly. If it is too large, then it
might oscillate between very large positive and negative weights.
Either way, the result is poor compression.
We can do better than this. First, note that if only one input is active,
then we can solve for the weights directly. If the desired output is
p, then for the weight between them,
w = g-1(p) = log p/(1 - p)
If we let p = N(1)/N (the fraction of times that the output was 1 in
the past), then we can get the same effect by setting the learning rate
to (N(0) + N(1))/N(0)N(1). (See my paper for proof).
This requires that we store along with each weight
the counts N(0) and N(1), the number of times the output was a 0 or 1
when the input was active. (These are called c0 and c1 in p5.cpp and
p6.cpp).
In practice we initialize the counts to 0.5 instead of 0 to avoid
probabilities of 0 or 1 (and an initially infinite learning rate).
So if you can compute the weights directly, why don't you?
Because this no longer works when more than one input is active
at a time. A neural network solves the more general problem of
multiple contexts which may or may not be independent. Regardless
of what happens, it will keep adjusting the weights until there is
no more error.
Is your learning rate still optimal in this case?
Not unless the inputs are independent. But if there are m
fully dependent inputs (all on or all off at the same time), then
their combined effect is to increase the learning rate by a factor
of m. For that reason, I introduced a constant called the
long term learning rate (NL in the code), and set the
learning rate to NL x (N(0) + N(1))/N(0)N(1).
Since the inputs are neither fully independent or fully dependent,
NL should be somewhere between 1 and 1/m. I found that values
around 1/sqrt(m) (about 0.4 for m = 5) work well in practice
for text compression.
Why is it called a long term learning rate?
Because the effect is to base predictions on all of the input,
regardless of how long ago it occurred. For instance, if the input is
that thatch thaw the theatre theft th_
then it will assign the same probability to a and e,
even though the most recent statistics suggest that e is more
likely.
How do you adapt to short term statistics?
By reintroducing a constant called the short term learning rate
(NS). Then the learning rate becomes:
NS + NL x (N(0) + N(1))/N(0)N(1)
The effect is to bias the statistics in favor of the last 1/NS
occurrences of the context, and "forgetting" earlier examples.
What short term learning rate should I use?
It depends on the data. If the data is stationary (statistics
do not change over time), then the optimal value is 0. For
text, I found the following approximate values to work well.
Context
Length NS
1 0.08
2 0.15
3 0.2
4 0.2
5 0.2
In text, character frequencies tend to be constant (e is the
most common letter in nearly all forms of text). This is not true
for word-length contexts. Here, the recent occurrence of a word
makes it likely to appear again. This is called the "cache" effect.
Where does your function g(.) come from?
In a neural network, g(.) (also called the squashing function)
has to have a range of (0, 1) (to represent a valid probability) and
has to be monotonically increasing (so that training adjusts the
weights in the right direction). There are lots of other functions that
meet this requirement (for instance, arctan), but it can be shown
that g(x) = 1/(1 + e-x) satisfies the maximum entropy
principle, and therefore generalizes to new input data in the most
reasonable way.
What is the Maximum Entropy principle?
It states that the most likely joint distribution, given a partial
set of constraints, is the one with the highest entropy, or the
most uniform distribution. It is a strategy that we use all the time
to combine evidence from past experience to generalize to new
situations. For instance, suppose we know that a person with a
headache or a sore throat may have a cold (each with a certain probability)
and we wish to estimate the probability when both symptoms are present.
We are given the following facts:
- The probability of a person with no symptoms having
disease y (a cold) is P(y) = 0.001
- If symptom x1 only (a headache) is present,
the probability is P(y|x1) = 0.1
- If symptom x2 only (a sore throat) is present,
the probability is P(y|x2) = 0.5
What is P(y|x1,x2), the probability of having the
disease if both symptoms are present?
This is a partially constrained problem over the joint distribution
P(x1, x2, y). There is not enough information
to solve the problem. We suspect that the probability will be high
(as ME predicts),
but in fact it could be zero without violating any of the
given constraints.
For the more general case where we wish to find P(y|X) =
P(y|x1, x2, ...,
xn), the Maximum Entropy (ME) solution can be found by a
process called Generalized Iterative Scaling (GIS), and has the form
P(y|X) = 1/Z exp(Si
w0 + wixi)
where the wi are constants (weights) to be solved, and Z is a
constant chosen to make the probabilities add up to 1.
(See Rosenfeld 1996, or Manning and Schütze 1999).
GIS is essentially an algorithm for adjusting the weights, wi,
until the constraints are met, similar to neural network training.
In fact, when we solve for Z, we have our neural network equation.
P(y|X) = g(Si
w0 + wixi)
where g(x) = 1/(1 + e-x)
We don't always have to use GIS.
For our original example, we can solve for the weights directly to
confirm our intuition.
- by setting x1 and x2 to 0,
w0 = log 0.001/0.999 = -6.906
- by setting x1 to 1 and x2 to 0,
w1 = log 0.1/0.9 - w0 = 4.709
- by setting x1 to 0 and x2 to 1,
w2 = log 0.5/0.5 - w0 = 6.906
- P(y|x0,x1) = g(w0 +
w1 + w2) = g(4.709) = 1/(1 + e-4.709)
= 0.991
Why does your program use hash functions?
Recall that there is one input unit for each possible context. For
contexts of length 5, there would have to be
2565 = 1012 input units, the vast majority
of which would never be used. Instead, I map this huge set of contexts
into a smaller set of inputs (about 4 x 106) by using a hash
function. The input to the hash function is the context, treated as a
number, and the output is the index of the corresponding unit.
Why did you use x[1]=(s4&0xffffff)%4128511 ?
In p6.cpp, x[0] through x[4] are the indices of the units for the
contexts of length 1 through 5. s4 contains the last 4 bytes of
input. The &0xffffff masks off just the last 3 bytes.
The number 4128511 is a prime number slightly less than the total
number of input units (222). The result is to map
a 3 byte context (of which there are 16,777,216) into one of
4,128,511 units.
For the longer contexts, I used a slightly different method to
avoid having to do arithmetic on numbers longer than 32 bits, but
the effect is the same.
For the two byte context (65536 possibilities), I gave each
context its own input unit, so no hash function was needed.
For the longer contexts, I mapped them into the same space, so it
is possible that two contexts of different length might share the
same input unit.
What happens when two contexts share the same input unit?
There is a loss of compression ratio, because the contexts may
predict different characters, and there is no way for the neural network
to distinguish between them. However in text, contexts are not
uniformly distributed, so if there is a collision, one context is
likely to dominate over the other, minimizing the loss of compression.
What can be done to minimize collisions?
Two things. First, use more input units (and more memory). This is why
P6 compresses better than P5. The second is to use a hash function
that gives a fairly uniform or random distribution, as the
modulo prime number function does.
Another possibility is to use a data structure that avoids collisions
entirely, such as a tree or a bucket hash table. This would improve
compression on small files, but are not a solution, since all such
data structures would eventually fill up or exhaust memory.
It looks like your context lengths are 2 through 6
Actually, they are 1 to 5 characters plus the last 0 to 7 bits
of the current character.
Why does your neural network predict one bit at a time?
It is faster. Instead of estimating 256 probabilities for each character,
it estimates one probability for each bit. There are 8 bits (and predictions)
per character, but bit prediction is still 16 times faster. It also
means that there is only one output unit instead of 256.
Bit prediction is otherwise equivalent to character predition. For instance,
the ASCII code for e is 01100101, so we can estimate its probability
as the product of the probabilities for each bit:
P(e|th) =
P(0|th)P(1|th,0)P(1|th,01)P(0|th,011)P(0|th,0110)P(1|th,01100)P(0|011001)P(1|th,0110010).
There is a separate input unit for each of these 8 contexts.
Why did you use 222 input units?
I wanted to use 16 MB of memory. There are 4M units, and each unit
requires 4 bytes of memory. The weight wi uses 2 bytes, and
the counts N(0) and N(1) use 1 byte each.
What happens if the counts exceed 256 (1 byte)?
I divide both N(0) and N(1) by 2. This has the same effect as increasing
the short term learning rate NS by about 1/256.
What are the classes G and Sigma2 for?
They use fast table lookup to do some of the computation.
Why do you use scaled integer arithmetic?
It is faster than floating point.
How does scaled arithmetic work?
A real number is represented as an inteter and a scale factor, usually
a power of 2. For instance, the weights wi are represented
as a 16 bit integer scaled by 210 bits (1024). Thus,
the number 2.5 would be represented as 2.5 x 1024 = 2560. I use
powers of 2, because the scale factor can be changed by using the
bit shift operators (<< and >>), which are faster then
multiplication and division.
I still have another question.
Email me at mmahoney@cs.fit.edu
References
Bell, Timothy, Ian H. Witten, John G. Cleary (1989),
"Modeling for Text Compression",
ACM Computing Surveys (21)4, pp. 557-591, Dec. 1989.
Bloom, Charles, ppmz v9.1 (1997),
http://www.cco.caltech.edu/~bloom/src/ppmz.html
Manning, Christopher D., and Hinrich Schütze, (1999), Foundations
of Statistical Natural Language Processing, Cambridge MA: MIT Press.
Rosenfeld, Ronald (1996), "A maximum entropy approach to adaptive
statistical language modeling", Computer, Speech and Language, 10, see also
http://www.cs.cmu.edu/afs/cs/user/roni/WWW/me-csl-revised.ps.
Shannon, Claude, and Warren Weaver (1949),
The Mathematical Theory of Communication,
Urbana: University of Illinois Press.
Shannon, Cluade E. (1950), "Prediction and Entropy of Printed English",
Bell Sys. Tech. J (3) p. 50-64.
Turing, A. M., (1950) "Computing Machinery and Intelligence, Mind, 59:433-460